Sample Programs: Fireflies
To run a sample program, you need to install Panda3D. If you’re a Windows user, you’ll find the sample programs in your start menu. If you’re a Linux user, you’ll find the sample programs in /usr/share/panda3d.
Screenshots
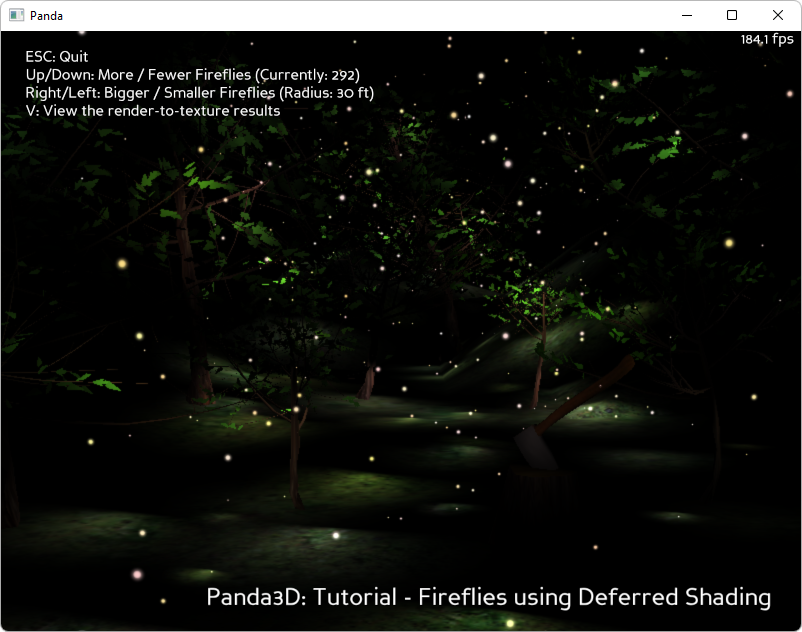
Explanation
A nature scene with 500 fireflies: how do you do a high-polygon scene with 500 lights, without a total performance collapse?
This sample program shows how to do Deferred Shading in Panda. You can have hundreds of lights, and all the lights affect all the models automatically. This is not expensive: the cost is only proportional to the number of actual lit pixels times the number of times each pixel is lit. That’s why fireflies make a perfect demonstration — you could never have 500 lights in a high-polygon scene without deferred shading. But perhaps even more important is the elegance of a rendering algorithm that automatically connects lights to the appropriate objects without the need for LightAttribs.
To understand how deferred shading works, first consider how ordinary shading works in plain OpenGL. In most fairly simple cases, the lighting equation boils down to:
final = diffuse color * dot(light vector, surface normal) * attenuation(surface position, light position and orientation)
Where the attenuation function depends on the type of light. So anyhow, this equation has four inputs:
The diffuse color.
The surface normal.
The surface position.
The light parameters.
The idea behind deferred shading is that during the rendering process, you don’t compute the final color. Instead, you store the values listed above in the framebuffer itself. Of course, you need a “fat framebuffer” to store all that data. In an image postprocessing step you scan the framebuffer and compute the final color.
Of course, that’s a lot of data to store in the framebuffer. The first optimization is not to store the light parameters. It is not necessary to store light parameters because the light parameters don’t vary from pixel to pixel — they’re constants.
Our second optimization involves surface position. Surface position can be inferred by calculating backward from the depth buffer. Each pixel on the screen represents a ray from the camera into the scene, and the depth value in the pixel indicates a distance along the ray. Because of this, it is not actually necessary to store surface position explicitly - it is only necessary to store depth values. Of course, OpenGL does that for free.
So the framebuffer now needs to store surface normal, diffuse color, and depth value (to infer surface position). In practice, most ordinary framebuffers can only store color and depth - they don’t have any place to store a third value. So we need to use a special offscreen buffer with an “auxiliary” bitplane. The auxiliary bitplane stores the surface normal.
So then, there’s the final postprocessing pass. This involves combining the diffuse color texture, the surface normal texture, the depth texture, and the light parameters into a final rendered output. The light parameters are passed into the postprocessing shader as constants, not as textures.
If there are a lot of lights, things get interesting. You use one postprocessing pass per light. Each pass only needs to scan those framebuffer pixels that are actually in range of the light in question. To traverse only the pixels that are affected by the light, just render the illuminated area’s convex bounding volume.
The shader to store the diffuse color and surface normal is trivial. But the final postprocessing shader is a little complicated. What makes it tricky is that it needs to regenerate the original surface position from the screen position and depth value. The math for that deserves some explanation.
We need to take a clip-space coordinate and depth-buffer value \(\begin{pmatrix}x_{clip}&y_{clip}&z_{clip}&w_{clip}\end{pmatrix}\) and unproject it back to a view-space \(\begin{pmatrix}x_{view}&y_{view}&z_{view}\end{pmatrix}\) coordinate. Lighting is then done in view-space.
Okay, so here’s the math. Panda uses the projection matrix to transform view- space into clip-space. But in practice, the projection matrix for a perspective camera always contains four nonzero constants, and they’re always in the same place:
The result is that the panda projection matrix boils down to these simple equations:
Look out, there has been a coordinate system change! In the scene graph, Z corresponds to “up”, but in clip-space, Z is the depth value (and X,Y address a pixel).
After panda calculates clip-space coordinates, it divides by W. Finally, it rescales the depth-value:
So now we have some equations defining \(\begin{pmatrix}x_{clip}&y_{clip}&z_{clip}&w_{clip}\end{pmatrix}\) in terms of \(\begin{pmatrix}x_{view}&y_{view}&z_{view}\end{pmatrix}\), and \(\begin{pmatrix}x_{screen}&y_{screen}&z_{screen}\end{pmatrix}\) in terms of \(\begin{pmatrix}x_{clip}&y_{clip}&z_{clip}&w_{clip}\end{pmatrix}\). It’s basic algebra to solve these equations for \(\begin{pmatrix}x_{view}&y_{view}&z_{view}\end{pmatrix}\) in terms of \(\begin{pmatrix}x_{screen}&y_{screen}&z_{screen}\end{pmatrix}\). Here, I have shown all my algebraic steps:
To save our vertex and pixel shaders a little work, we can precompute these constants:
So, here are the equations in their final form:
Back to the List of Sample Programs: